
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- dfs
- 백준
- 성적평가
- 매개변수탐색
- 연결요소
- 소프티어
- 물채우기
- 오퍼레터
- 파라메트릭
- upper_bound
- 처우산정
- boj #19237 #어른 상어
- 백트래킹
- BOJ
- Kafka
- msSQL
- 13908
- incr
- 경력
- BFS
- softeer
- 기술면접
- compose
- 처우협의
- Docker
- 이분탐색
- 퇴사통보
- @P0
- OFFSET
- 6987
- Today
- Total
기술 블로그
카프카 기본 개념 설명 본문
1. 카프카 생태계
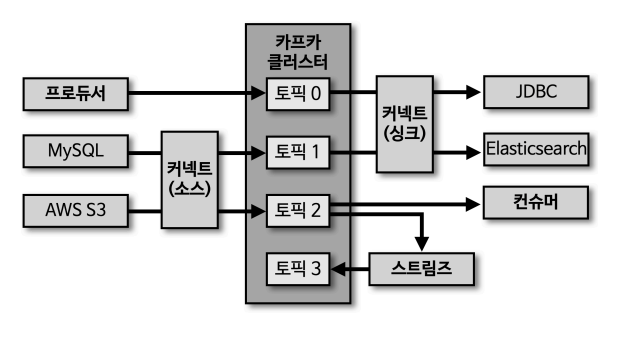
프로듀서, 컨슈머, 스트림즈 → Java 기반
- 커넥트(소스) : 프로듀서의 역할
- 커넥트(싱크) : 컨슈머의 역할
2. 브로커, 클러스터, 주키퍼

- 브로커 : 카프카 클라이언트와 데이터를 주고받기 위해 사용하는 주체이자, 데이터를 분산 저장하여 장애가 발생하더라도 안전하게 사용할 수 있도록 도와주는 애플리케이션
- 하나의 서버에는 한 개의 카프카 브로커 프로세스가 실행된다.
- 3대 이상의 브로커 서버를 1개의 클러스터로 묶어서 운영해야한다.
3. 여러개의 카프카 클러스터가 연결된 주키퍼

- 카프카 클러스터로 실행하기 위해서는 주키퍼가 필요함
- 주키퍼의 서로 다른 znode에 클러스터를 지정하면 됨
- root znode에 각 클러스터별 znode를 생성하고, 클러스터 실행시 root가 아닌 하위 znode로 설정
- 카프카 3.0부터는 주키퍼가 없어도 클러스터 동작 가능
4. 브로커의 역할
- 컨슈머 오프셋 저장 : 컨슈머 그룹은 토픽이 특정 파티션으로부터 데이터를 가져와서 처리하고, 이 파티션의 어느 레코드까지 가져갔는지 확인하기 위해 오프셋을 커밋함. 커밋한 오프셋은 __consumer_offsets 토픽에 저장됨. 여기에 저장된 오프셋을 토대로 컨슈머 그룹은 다음 레코드를 가져가서 처리. → 한 마디로, 커밋 정보를 저장하는 것으로 생각.
- 그룹 코디네이터 : 컨슈머 그룹의 상태를 체크하고 파티션을 컨슈머와 매칭되도록 분배하는 역할. 빠짐 없이 일할 수 있도록 분배.
- 데이터의 저장 : 카프카를 실행할 때, config/server.properties의 log.dir 옵션에 정의한 디렉토리에 데이터를 저장함. 코픽 이름과 파티션 번호의 조합으로 하위 디렉토리를 생성하여 데이터를 저장.
기타)
- log에는 메시지와 메타데이터를 저장.
- index는 메시지의 오프셋을 인덱싱한 정보를 담은 파일.
- timeindex 파일에는 메시지에 포함된 Timestamp값을 기준으로 인덱싱한 정보가 담겨 있음.
5. 로그와 세그먼트

- log.segment.bytes : 바이트 단위의 최대 세그먼트 크기 지정. 기본값은 1GB
- log.roll.ms(hours) : 세그먼트가 신규 생성된 이후 다음 파일로 넘어가는 시간 주기. 기본값은 7일
* 가장 최근 프로듀서가 레코드에 전송하면, active 세그먼트에 데이터가 저장됨. FIFO 구조.
* 가장 처음의 오프셋 번호가 파일의 이름.
00010.log → 오프셋 10부터 ~
00020.log → 오프셋 20부터 ~
* 가장 마지막 세그먼트 파일(쓰기가 일어나고 있는 파일)을 active 세그먼트라고 부른다.(삭제 대상에 포함이 되지 않음)
* active 세그먼트가 아닌 세그먼트는 retention 옵션에 따라 삭제 대상이 된다.
* ~~.log = 세그먼트
6. 세그먼트와 삭제 주기
- retention.ms(minutes, hours) : 세그먼트를 보유할 최대 기간. 기본 값은 7일. (저장될 디스크의 용량을 고려해야함..)
- retention.bytes : 파티션당 로그 적재 바이트 값. 기본 값은 -1(지정하지 않음)
- log.retention.check.interval.ms : 세그먼트가 삭제 영역에 들어왔는지 확인하는 간격. 기본 값은 5분
7. 세그먼트의 삭제
- 카프카에서 데이터는 세그먼트 단위로 삭제가 발생
- 오프셋 단위로 삭제를 하지 못함.(수정도 불가능)
8. cleanup.policy=compact
(cleanup.policy=delete는 위에서 설명. 5번 참고)
- compact : 특정 로직을 통해 동일한 메시지 KEY 중에서 가장 최신의 메시지만 남김.
- 단, active 세그먼트는 대상에서 제외.
9. 테일/헤드 영역, 클린/더티 로그
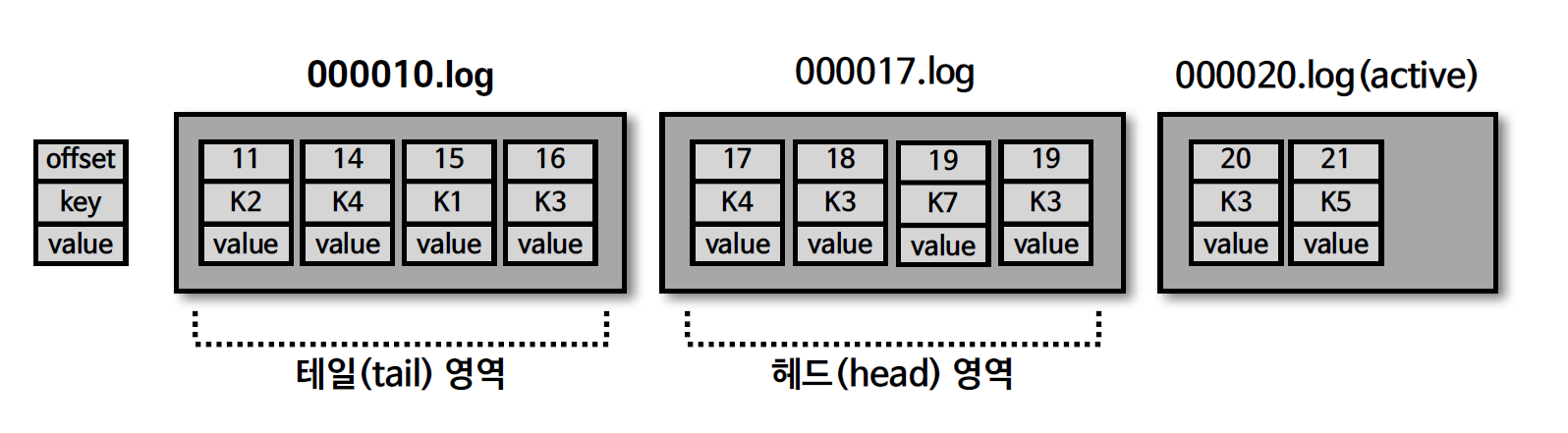
- 테일 영역 : 압축 정책에 의해 압축이 완료된 레코드들. clean 로그라고도 부른다. 중복 메시지 키가 없다.
- 헤드 영역 : 압축이 되기 전의 레코드들. dirty 로그 라고도 부른다. 중복됨 메시지 키가 있다.
10. min.cleanable.dirty.ratio
- 데이터 압축 시작 시점은 min.cleanable.dirty.ratio 옵션 값을 따른다.
- min.cleanable.dirty.ratio 옵션 값은 active 세그먼트를 제외한 세그먼트에 남아 있는 테일 영역의 레코드 개수와 헤드 영역의 레코드 개수의 비율.
- 0.9로 설정하면 한 번에 많은 데이터가 줄어든다. 그러나, 0.9 비율이 될 때 까지 용량을 차지하므로 용량 효율이 좋지 않음. 그리고, 테일 영역의 clean 레코드 개수에 비해 헤드 영역의 dirty 레코드 개수가 많아짐.
- 0.1로 설정하면 최신 데이터를 유지할 수 있지만, 압축이 자주 발생해서 브로커 입장에서는 부담.
11. 복제(Replication)
- 카프카를 운영할 때, 가장 중요함.
- 카프카를 장애 허용 시스템으로 동작하도록 하는 원동력
- 클러스터로 묶인 브로커 중 일부에 장애가 발생하더라도 데이터를 유실하지 않고, 안전하게 사용하기 위함.
- 복제는 파티션 단위로 이루어짐.
- 토픽을 생성할 때, 파티션의 복제 개수도 같이 설정되는데 최솟값은 1이고, 최댓값은 브로커 개수. 보통 2, 3, 5.
- 아래 12번은 개수를 3으로 설정했을 때이다.
12. 리더와 팔로워

- 복제된 파티션은 리더와 팔로워로 구성
- 프로듀서 또는 컨슈머와 직접 통신하는 파티션을 리더, 나머지 복제 데이터를 가지고 있는 파티션을 팔로워.
- 복제를 하면, 용량이 증가됨.
- 복제를 통해 데이터를 안전하게 사용할 수 있다는 강력한 장점 때문에 카프카를 운영할 때 2 이상의 복제 개수를 정하는 것이 중요함
13. 브로커에 장애가 발생한 경우
- 브로커가 다운되면, 해당 브로커에 있는 리더 파티션은 사용할 수 없기 때문에 팔로워 파티션 중 하나가 리더 파티션 지위를 넘겨 받음.
- 이를 통해, 데이터가 유실되지 않고 컨슈머나 프로듀서와 데이터를 주고 받도록 동작할 수 있음.]
- 토픽 마다, 복제 개수를 다르게 설정하여 운영하기도 함.
- 데이터가 일부 유실되어도 무관하고, 데이터 처리 속도가 중요하다면 1 또는 2로 설정. metric과 같은 경우.
- GPS 정보를 매초마다 자동차에게 보낸다면,(1분에 60개 가정) 1~3개 정도는 유실되어도 큰 상관이 없다.
- 금융 정보와 같이 유실이 일어나면 안 되는 데이터의 경우 복제 개수를 3으로 설정.

14. ISR(In-Sync-Replicas)

- ISR은 리더 파티션과 팔로워 파티션이 모두 싱크가 된 상태를 의미함.
- 싱크가 되었다는 것은 오프셋의 개수가 같다.
15. unclear.leader.election.enable
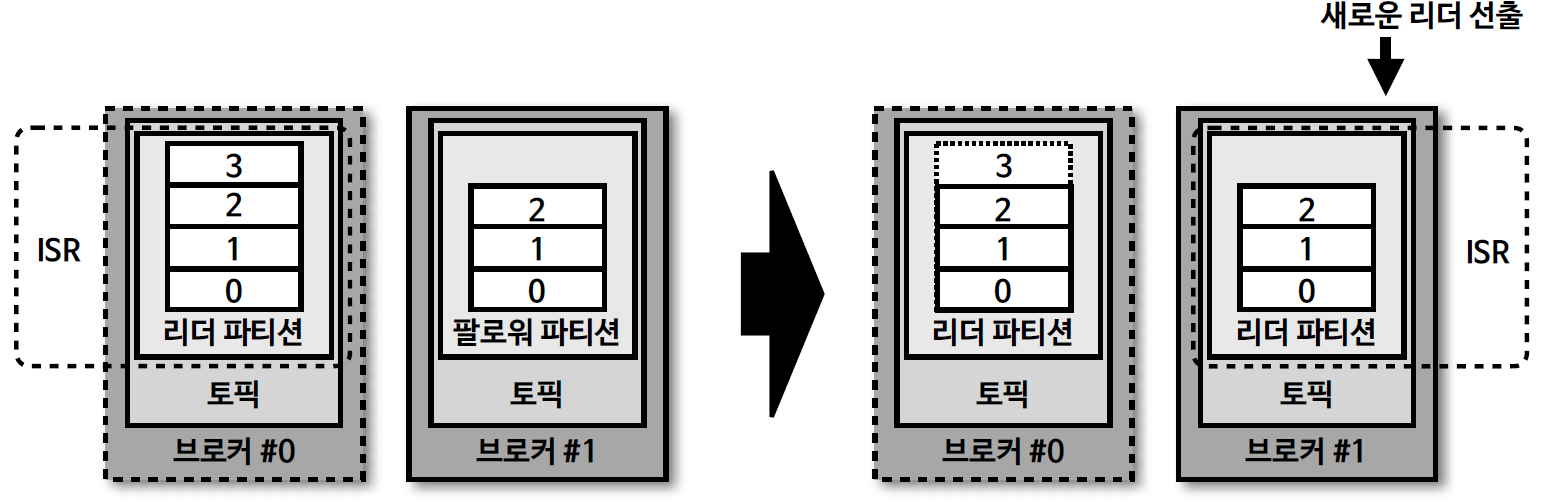
- 리더 파티션의 데이터를 모두 복제하지 못한 상태이고, 이렇게 싱크가 되지 않은 팔로워 파티션이 리더 파티션으로 선출되면 데이터가 유실될 수 있다.
- 유실이 발생하더라도 서비스를 중단하지 않고, 지속적으로 토픽을 사용하고 싶다면, ISR이 아닌 팔로워 파티션을 리더로 선출하도록 설정할 수 있다.
- unclear.leader.election.enable=true : 유실을 감수함. 복제가 안된 팔로워 파티션을 리더로 승급.
- unclear.leader.election.enable=false : 유실을 감수하지 않음. 해당 브로커가 복구될 때까지 중단.
16. 토픽과 파티션

- 토픽은 카프카에서 데이터를 구분하기 위해 사용하는 단위.
- 토픽은 1개 이상의 파티션을 소유.
- 파티션에는 프로듀서가 보낸 데이터들이 들어가 저장되어 있는데, 이 데이터를 레코드라고 함.
- 먼저 들어간 레코드는 컨슈머가 먼저 가져감. FIFO 구조.
- 다만, 가져간다고 해서 카프카에서 삭제를 하는 것이 아님.
- 파티션의 레코드는 컨슈머가 가져가는 것과 별개로 관리. 이러한 특징 때문에 토픽의 레코드는 다양한 목적을 가진 여러 컨슈머 그룹들이 토픽의 데이터를 여러번 가져갈 수 있음.
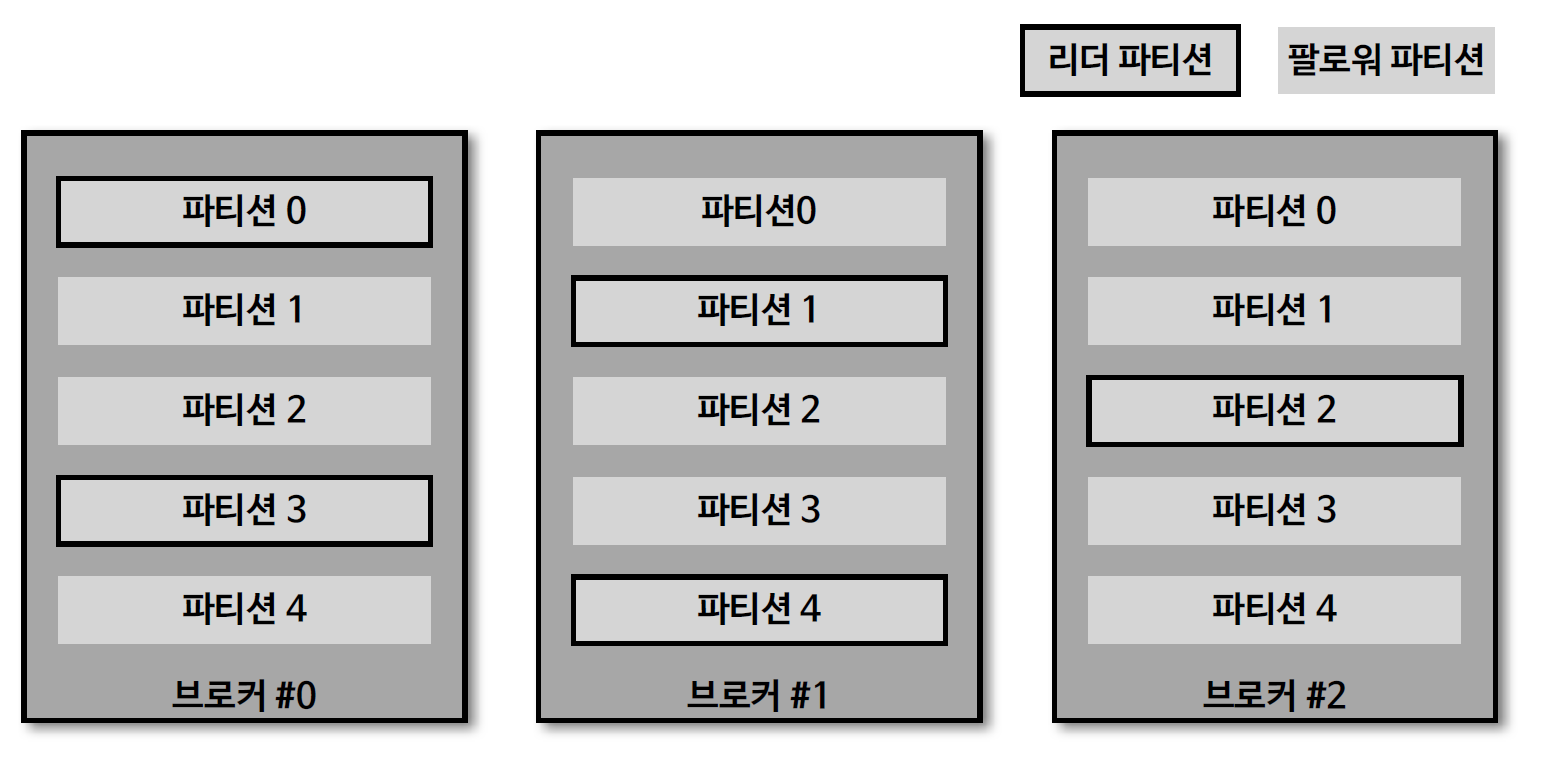
17. 토픽 생성시 파티션이 배치되는 방법
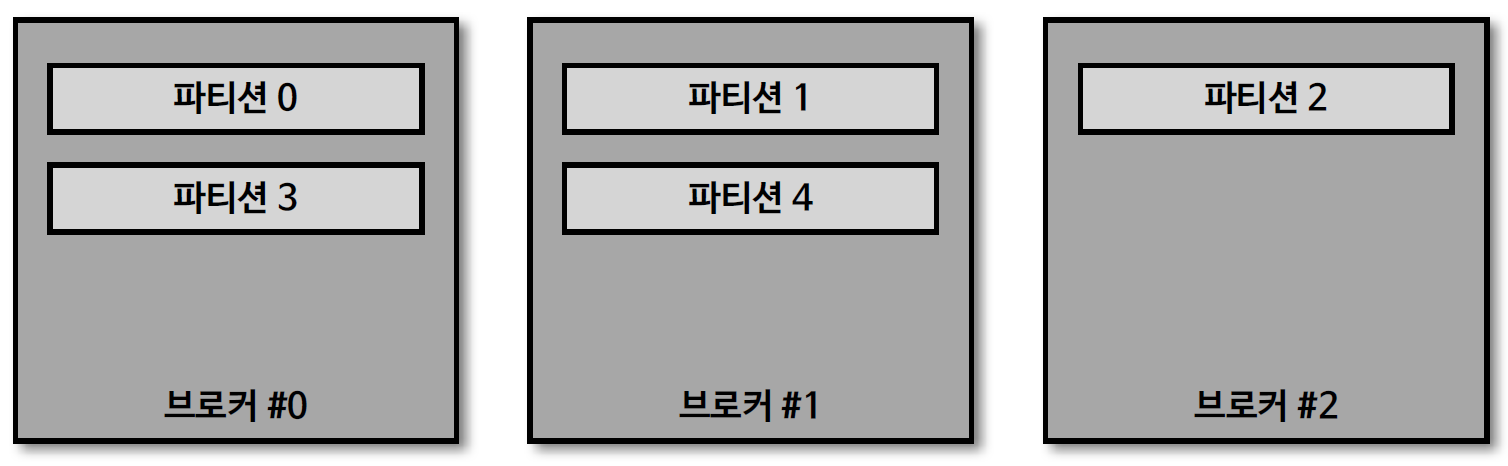
- 파티션이 5개인 토픽을 생성했을 경우 그림과 같이 0번 브로커부터 시작하여, round-robin 방식으로 리더 파티션들이 생성. → 분산되어 공정하게 데이터를 처리
- 카프카 클라이언트는 리더 파티션이 있는 브로커와 통신하여, 데이터를 주고 받으므로 여러 브로커에 골고루 네트워크 통신을 하게 된다.
- 데이터가 특정 서버(여기서는 브로커)와 통신이 집중되는(hot spot) 현상을 막고, 선형 확장(linear scale out)을 하여, 데이터가 많이지더라도 자연스럽게 대응할 수 있다.
18. 특정 브로커에 파티션이 쏠린 현상

- 특정 브로커에 파티션이 몰리는 경우에는 kafka-reassign-partitions.sh 명령으로 파티션을 재분배할 수 있다.
19. 파티션 개수와 컨슈머 개수의 처리량

- 파티션은 카프카의 병렬 처리의 핵심으로써 그룹으로 묶인 컨슈머들이 레코드를 병렬 처리할 수 있도록 매칭됨.
- 컨슈머의 처리량이 한정된 상황에서 많은 레코드를 병렬로 처리하는 가장 좋은 방법은 컨슈머의 개수를 늘려 스케일 아웃하는 것이다.
- 컨슈머 개수를 늘림과 동시에 파티션 개수도 늘리면 처리량이 증가
- 컨슈머와 파티션의 관계는 1:1이다.
20. 파티션 개수를 줄이는 것은 불가능

- 카프카에서 파티션 개수를 줄이는 것은 지원하지 않는다.
- 그러므로, 파티션을 늘리는 작업을 할 때는 신중히 파티션 개수를 정해야 한다.
'온라인강의 > 아파치 카프카 애플리케이션' 카테고리의 다른 글
| 정리 (0) | 2023.09.10 |
|---|---|
| 카프카 브로커와 클라이언트가 통신하는 방법 및 정리 (0) | 2023.09.10 |
| 토픽 이름 제약 조건 (0) | 2023.09.10 |
| 레코드 (0) | 2023.09.07 |
| 아파치 카프카의 역사와 미래 (0) | 2023.09.05 |



